Stable Diffusion




**Excerpt from the relevant “ComfyUI dev” Matrix room:** *matt3o*\ and what is it then? *comfyanonymous*\ "safety training" *matt3o*\ why does it trigger on certain keywords and it's like it's scrambling the image? *comfyanonymous*\ the 2B wasn't the one I had been working on so I don't really know the specifics *matt3o*\ I was even able to trick it by sending certain negatives *comfyanonymous*\ I was working on a T5 only 4B model which would ironically had been safer without breaking everything\ because T5 doesn't know any image data so it was only able to generate images in the distribution of the filtered training data *comfyanonymous*\ but they canned my 4B and I wasn't really following the 2B that closely […] *comfyanonymous*\ yeah they did something with the weights\ the model arch of the 2B was never changed at all *BVH*\ weights directly?\ oh boy, abliteration, the worst kind *comfyanonymous*\ also they apparently messed up the pretraining on the 2B so it was never supposed to actually be released […] *comfyanonymous*\ yeah the 2B apparently was a bit of a failed experiment by the researchers that left\ but there was a strong push by the top of the company to release to 2B instead of the 4B and 8B **Additional excerpt (after the Reddit post) from Stable Diffusion Discord “#sd3”:** *comfy*\ Yes I resigned over 2 weeks ago and Friday was my last day at stability



 github.com
github.com
Basic ComfyUI workflows without 10k custom nodes or impossible to follow workflows.

 www.forbes.com
www.forbes.com
https://archive.is/FkzdE







I created a [custom SDXL Lora](https://huggingface.co/piebro/factorio-blueprint-visualizations-sdxl-lora) using my [dataset](https://huggingface.co/datasets/piebro/factorio-blueprint-visualizations). I created the dataset using a previous generative art tool I build to visualize factorio blueprints: https://github.com/piebro/factorio-blueprint-visualizer. I like the lora to create interesting patterns.        
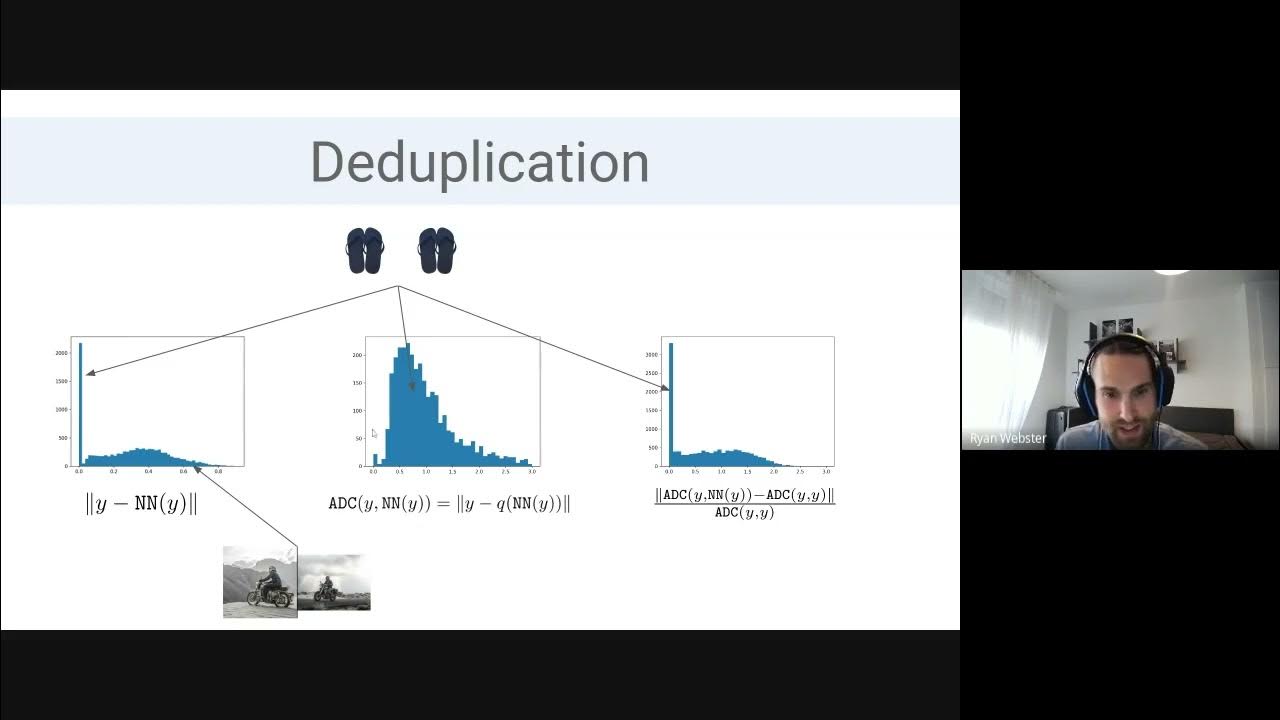

I don't know why its cracking me up so much, I dont know what I was expecting.. but also, I can't find any easy reason why this is happening, maybe an artist name i cant find now? A product name translation? ~~Stable Diffusion XL doesn't seem to replicate the same results~~ (actually kinda @ 768px instead of 512) any?? Stable diffusion ~~1.x~~ model with only positive prompt: ``` turbotits ``` | Settings | Image | | -- | -- | | Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 912261969, Size: 512x512, Model hash: f968fc436a, Model: **analogMadness_v50**, VAE hash: 735e4c3a44, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Version: v1.6.0-2-g4afaaf8a |  | | Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 1212726575, Size: 512x512, Model hash: 9aba26abdf, Model: **deliberate_v2**_sd1.5, VAE hash: 735e4c3a44, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Version: v1.6.0-2-g4afaaf8a | | | Steps: 20, Sampler: DPM++ 2M, CFG scale: 7, Seed: 1020297828, Size: 512x512, Model hash: af9ab7cc05, Model:**realcartoonPixar_v2**_sd1.5, VAE hash: 735e4c3a44, VAE: animevae.pt, ADetailer model: yolov8n.pt, ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer ControlNet model: control_v11p_sd15_inpaint [ebff9138], ADetailer ControlNet module: inpaint_global_harmonious, ADetailer version: 23.11.1, ControlNet 0: "Module: inpaint_global_harmonious, Model: control_v11p_sd15_inpaint [ebff9138], Weight: 1.0, Resize Mode: ResizeMode.INNER_FIT, Low Vram: False, Guidance Start: 0.0, Guidance End: 1.0, Pixel Perfect: True, Control Mode: ControlMode.BALANCED, Save Detected Map: True", Version: v1.6.0-2-g4afaaf8a |  | | Steps: 20, Sampler: DPM++ 2M, CFG scale: 7, Seed: 2311419033, Size: 512x512, Model hash: cc6cb27103, Model: **v1-5-pruned-emaonly**, VAE hash: 735e4c3a44, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Version: v1.6.0-2-g4afaaf8a |  | |Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2505533199, Size: 512x512, Model hash: fc2511737a, Model: **chilloutmix_NiPrunedFp32Fix**.sd1.5, VAE hash: 735e4c3a44, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Clip skip: 2, Version: v1.6.0-2-g4afaaf8a |  | | Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3851799520, Size: 512x512, Model hash: fe4efff1e1, Model: **HuggingFace_SD1.4**, Clip skip: 2, Version: v1.6.0-2-g4afaaf8a |  | | Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2906017088, Size: 768x768, Model hash: e6bb9ea85b, Model: ****sdXL_v10VAEFix****, Version: v1.6.0-2-g4afaaf8a |  | ___________ _____________ some models seem to show better results using clip skip 1 (vs. 2). Anyway, I got a chuckle from it. On a more utilitarian note, i suppose things like this could be used to gauge how "far" from an unknown merge point you are from a base model perhaps? (like DNA evolution i mean, wording it poorly) settings for post/linked image: Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 366961196, Size: 512x704, Model hash: 8c4042921a, Model: aZovyaRPGArtistTools_v3VAE_sd1.5, VAE hash: 735e4c3a44, VAE: vae-ft-mse-840000-ema-pruned.safetensors, Denoising strength: 0.52, Hires upscale: 1.5, Hires upscaler: Latent, Refiner: centerflex_v28.sd1.5_safetensors [02e248bf1b], Refiner switch at: 0.8, Version: v1.6.0-2-g4afaaf8a

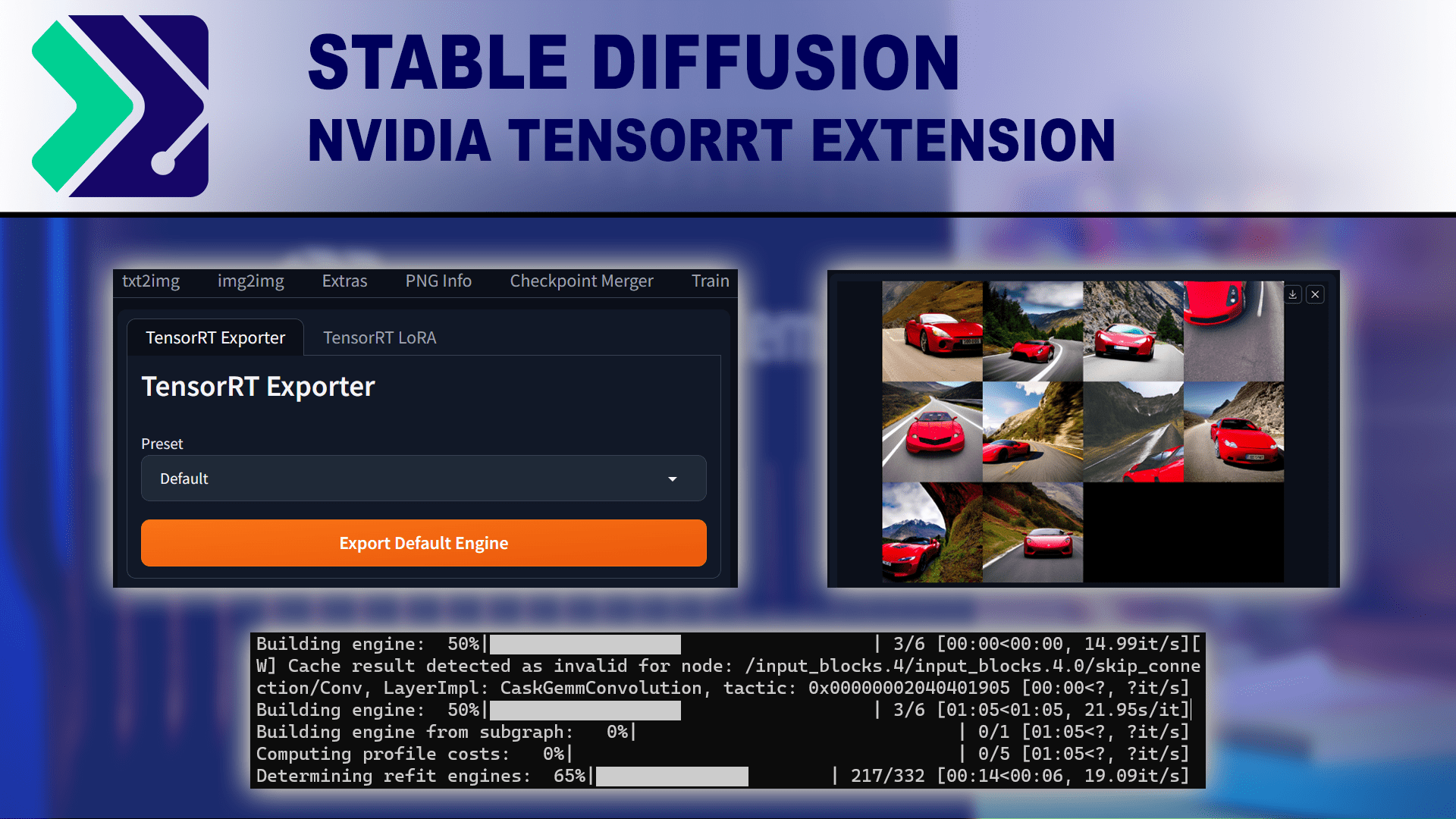

Using ParchArtXL civitai.com/models/141471/parchartxl




 stability.ai
stability.ai
Stability AI has just announced the release of StableCode, its very first LLM generative AI product for coding.
I was curious, do you run Stable Diffusion locally? On someone else's server? What kind of computer do you need to run SD locally?

She Looks cool and funny but she is a hell of a monster.




Prompt created locally via wizardLM-7b > Describe an eerie image of a mountain landscape >An eerie image of a mountain landscape could be one where the sun is setting behind the mountains, casting long shadows across the valleys below. The sky may be painted with a palette of oranges, purples, and pinks as the light fades away into darkness. The peaks of the mountains are shrouded in mist, creating a sense of mystery and intrigue. The silence is broken only by the occasional howl of a wolf or the rustling of leaves in the wind. It's a scene that evokes a sense of solitude and isolation, making it feel like you're at the edge of the world. Image created locally via >Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 4.5, Seed: 2599999378, Size: 512x512, Model hash: 4199bcdd14, Model: revAnimated_v122, Version: v1.3.0 >Time taken: 13.70s

This one was fun to work on. Used Inkpunk Diffusion - no img2img or controlnet - straight prompt editing.

I worked on this one for a family member who owns a blue Alfa Romeo Giulia. No post processing, I just used Inkpunk Diffusion model and kept running and tweaking prompts then upscaled my favorite..
the last post was about a week ago
Stable Diffusion
!stablediffusion@lemmy.mlWelcome to the Stable Diffusion community, dedicated to the exploration and discussion of the open source deep learning model known as Stable Diffusion.
Introduced in 2022, Stable Diffusion uses a latent diffusion model to generate detailed images based on text descriptions and can also be applied to other tasks such as inpainting, outpainting, and generating image-to-image translations guided by text prompts. The model was developed by the startup Stability AI, in collaboration with a number of academic researchers and non-profit organizations, marking a significant shift from previous proprietary models that were accessible only via cloud services.